Tuto SEO : Comment détecter votre contenu dupliqué ?
Article publié le 29 May 2019, 13 h 29 min
Comment détecter vos contenus dupliqués ?
Dans cet article nous allons voir comment détecter rapidement, et gratuitement les contenus dupliqués internes sur votre site. Pour ce tuto SEO vous allez avoir besoin de plusieurs logiciels gratuits : Xenu – Google Drive (sheets) – Plugin Xpath de Chrome.
Le principe est le suivant : à l’aide de Google Drive, vous allez récupérer automatiquement les éléments qui vous intéressent dans une page, à l’aide de Xpath. Ensuite, avec quelques requêtes et formules, vous allez pouvoir détecter les URLs qui posent problème.
Etape 1 : Récupérer la liste de vos URLs
Les solutions sont nombreuses pour récupérer la liste de vos URLs : Avec Google Analytics, Google Search Console, votre propre sitemap, où en lançant un crawl. Nous allons opter pour cette dernière solution.
Ouvrez votre logiciel de Crawl favori : Screaming Frog ou Xenu, et lancer une analyse. Avec Xenu :
File > Check URL
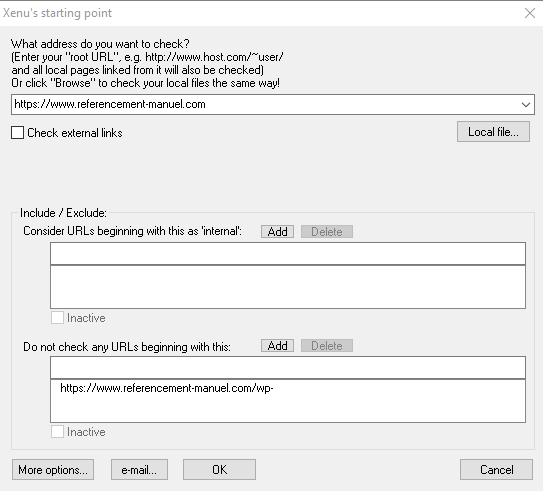
Dans votre analyse, il faudra supprimer tous les css, images, JS, medias etc. On ne gardera que les URLs qui répondent en 200 et au format HTML.
Lorsque le crawl est terminé, générez un rapport, et copiez la liste des URLs : “List of valid URLs you can submit to a search engine:”
Etape 2 : Récupérer les éléments à analyser avec Google Sheets
Ouvrez une nouvelle feuille Google Sheets, et collez les URLs dans la colonne A.
Dans la colonne B : Title
Dans la colonne C : Meta description
Dans la colonne D : H1
Dans la colonne E : Le div où votre contenu dupliqué peut être.
Pour récupérer ces éléments, nous allons utiliser la fonction IMPORTXML. Cette fonction prend deux paramètres : L’url à analyser et le chemin Xpath à récupérer.
Voici les Xpath pour les différents éléments :
Title : //title
Meta desc : //meta[@name=’description’]/@content
H1: //h1
Pour récupérer le contenu du div dans lequel votre texte à analyser est inséré, vous pouvez utiliser le plug in chrome Xpath Helper : https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
Une fois installé, rendez vous sur la page sur laquelle vous voulez récupérer le texte à analyser, et lancez Xpath Helper (ctrl + alt + shift + X). La console apparaît alors. Ensuite, appuyez sur Shift tout en survolant à la souris le Div où votre texte est présent. Relâchez la touche Shift, et votre chemin Xpath apparaît dans la console.
Ensuite, utilisez ce chemin Xpath dans Google Sheets pour récupérer les valeurs.
Retournez dans Google Sheets, et utilisez dans les colonnes B,C,D


Ensuite, il faut attendre que Google charge les informations, si votre site est très volumineux, cela peut prendre plusieurs jours. Si c’est un petit site, c’est quasiment instantané.
Voici le résultat une fois que tout est chargé :
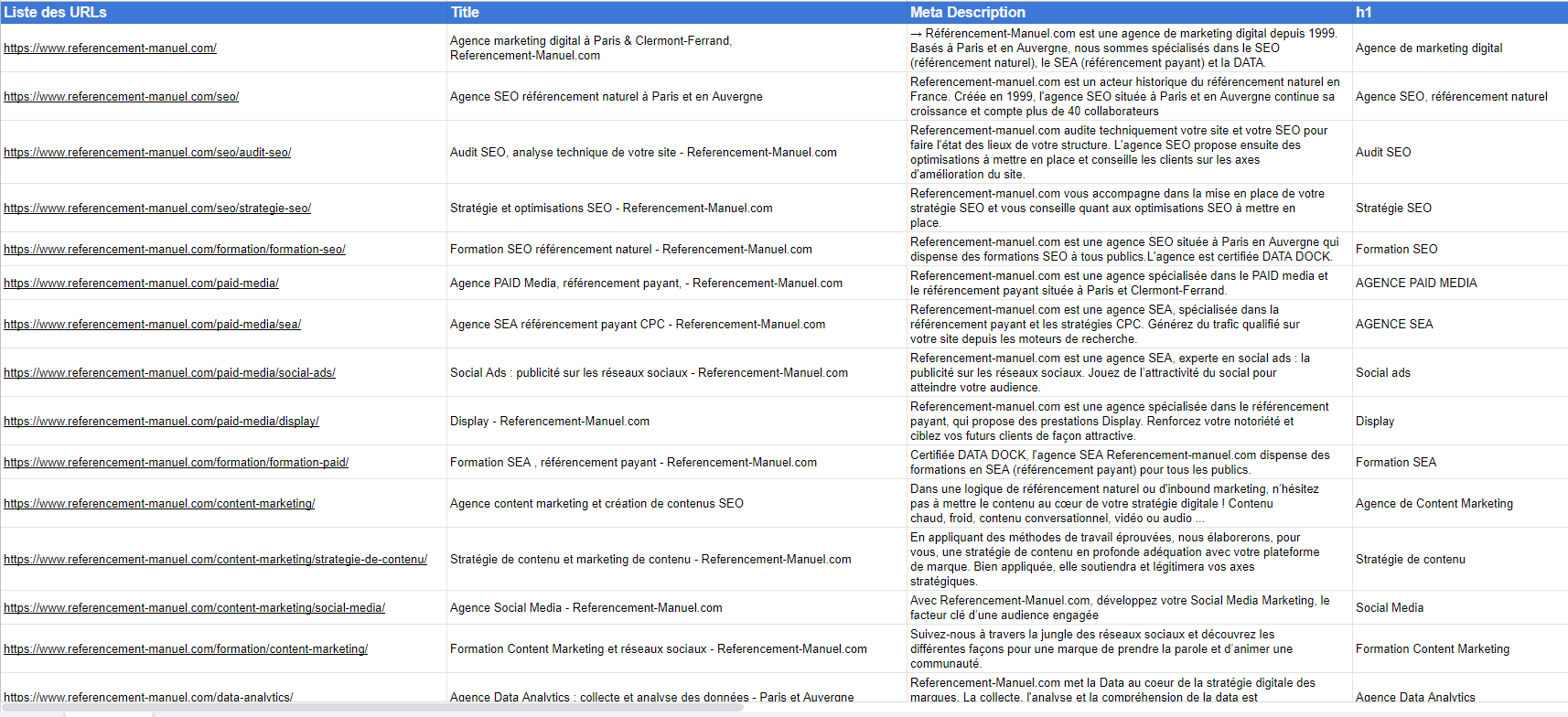
Éventuellement, en colonne E : Le contenu texte de votre chemin Xpath personnalisé.
Etape 3 : Trier les données et passer à l’action !
Maintenant que tout est chargé, nous vous conseillons de copier le tableau en entier, et de ne coller que les valeurs dans un nouveau Google Sheets ou Excel. De cette façon, vous travaillerez avec un fichier statique, qui sera plus facile à manipuler et à trier.
–> Dans sheets : Copiez tout votre tableau et faîtes file > New Sheet.
–> Dans la nouvelle feuille : Ctrl + V et choisissez l’option ‘Paste value Only’
A/ Détection des <title> trop long
Pour cela, ajoutez une nouvelle colonne à droite de la colonne <title>. Nous allons compter le nombre de caractères dans la cellule “title” associée
Tapez =len(B2) dans la colonne C2 (sous Google Sheets) // Dans excel : =NBCAR(B2)
Maintenant, filtrez votre tableau sur la colonne C, en ne gardant que ceux qui sont supérieurs à 68

Vous aurez un aperçu des titles qui sont tronqués dans la SERP, mais surtout, vous aurez un aperçu de vos titles qui sont beaucoup trop longs, la plupart du temps parce qu’il sont stuffés de mots clés. Vous devez donc les raccourcir et les réorientés en vous focalisant sur 1 ou deux mots clés.
B/ Détection des title, h1 et description dupliqués
Pour détecter les duplicatas des <title> : Copiez toute la colonne, et collez-la dans un nouvel onglet (Sheet 2).
Dans Google Sheet, sur la nouvelle feuille avec uniquement vos titles, faîtes : Data > Remove Duplicates. Vous allez ensuite obtenir le message suivant :
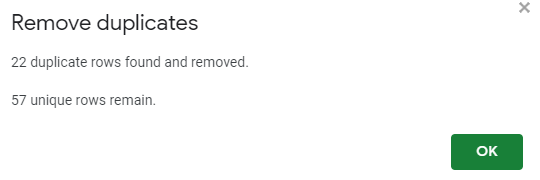
Vous allez alors savoir combien de <title> sont dupliqués. Maintenant, nous allons les identifier.
Pour cela, dans la Sheet 3, tapez, en colonne B =COUNTIF(Sheet1!$B$2:$B$80,A1) : Le premier paramètre correspond à la colonne dans la Sheet 1 où sont vos titles (n’oubliez pas de figer la plage avec $). Et le second paramètre correspond au title que vous voulez rechercher dans cette plage.
Vous allez obtenir le tableau suivant :

Toutes les lignes supérieures à 1 sont des duplicatas : vous pourrez les retrouver dans la Sheet 1 avec leurs URLs et corriger les <title>.
Répétez cette opération pour les autres éléments.
Autres utilisations
Vous pouvez utiliser la même mécanique pour récupérer :
Les canonicals : Si la canonical de la page, est différente de la page courante, il y a peut-être une anomalie.
Xpath : //link[@rel=’canonical’]/@href
La meta robots : Visualisez rapidement quelles sont les pages bloquées pour l’indexation
Xpath: //meta[@name=’robots’]/@content
Les balises alternate : Visualisez si les alternates sont bien paramétrées
Xpath : //link[@rel=’alternate’]/@href
Le nombre de liens : Visualisez le nombre de liens présents sur vos pages :
Xpath: //a/@href
Autres articles
Découvrez notre revue de presse du Marketing Digital de septembre 2020
Découvrez notre revue de presse du Marketing Digital de juin 2020